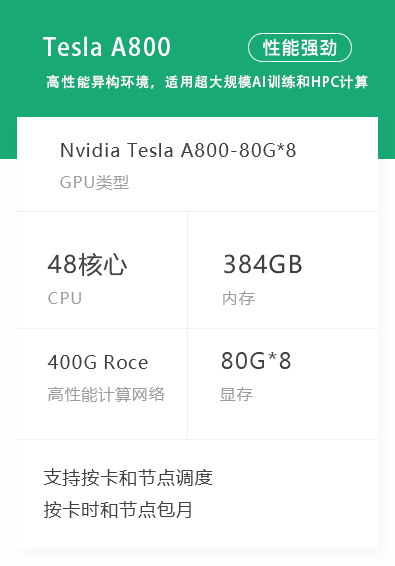
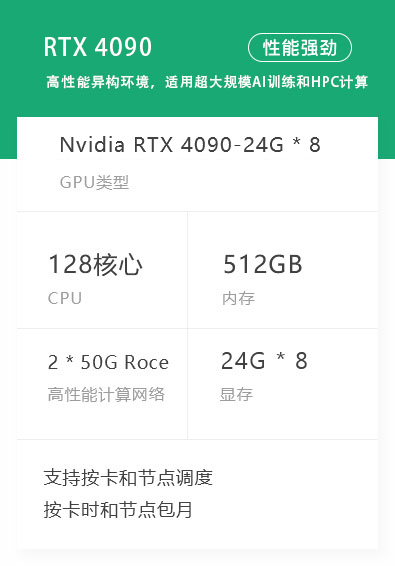
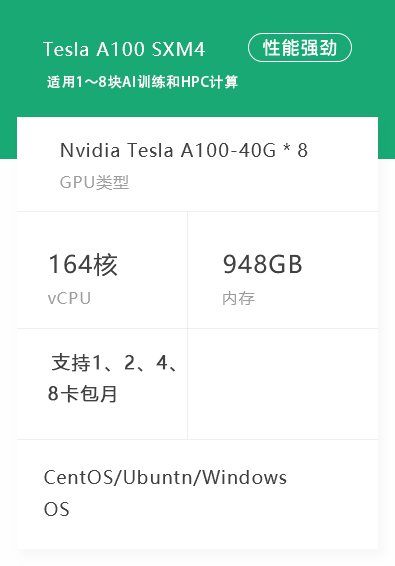
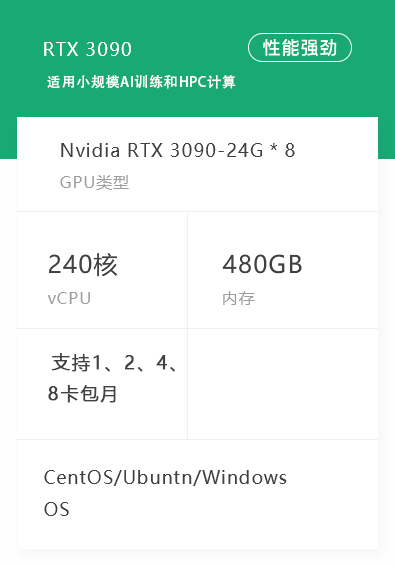
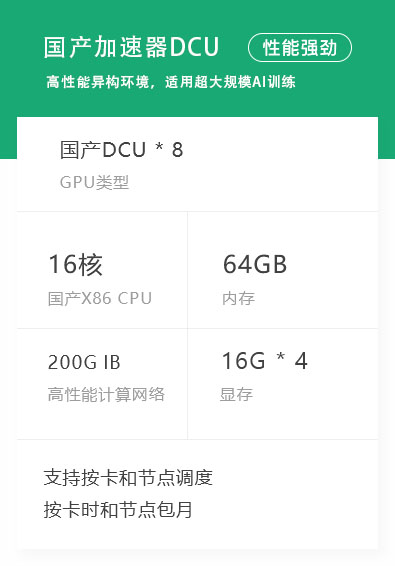
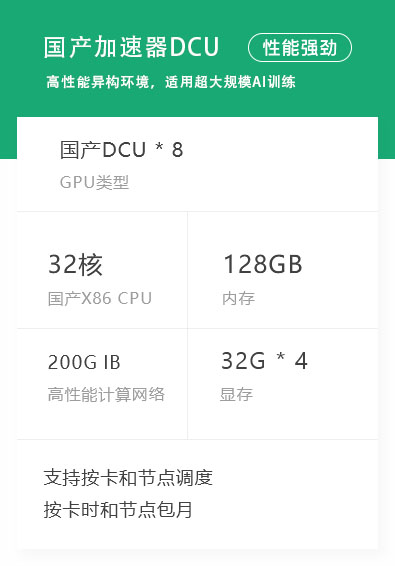
资源管理
管理多种类型的计算资源,包括CPU、GPU、FPGA等,根据任务需求动态分配资源,以确保任务可以高效地完成

成本优化
算力调度平台可以根据不同的计算资源价格、任务优先级和预算等因素,优化资源的使用方式,以降低计算成本

任务调度
根据任务的优先级、资源需求和预算等因素,智能地调度任务,合理利用计算资源,最大程度地提高计算资源的利用率和任务完成效率

容错和监控
平台具有容错机制,能够监控任务的运行状态,及时发现并处理任务失败或异常,确保任务顺利完成

安全性
平台需要具备安全的身份验证和访问控制机制,以确保计算资源和数据的安全性